Ah, the loop, so fundamental to programming it’s hard to imagine a single program without one. After all, what’s the use of calculating just one thing? Usually you have a big pile of things you want to calculate, which is why you need a computer in the first place.
I think one of the quickest ways to get a feel for a language is to study its looping constructs. I make no pretense that this is a complete or even an accurate list, but these are some of the general iteration patterns I’ve noticed in different languages.
Counter Variable Loop
for ( int i = 0; i <= 10; ++i ) {
do stuff with list[i];
}
The old C classic, with deeper roots, I believe, in FORTRAN or PASCAL or both. Successive values of an integer counter are used to retrieve input from an array. Very efficient for small data sets, but requires the entire input to be stored as an array in memory. Also requires the looping code to know about the structure of the input, so not very adaptable. But surprisingly resiliant: Perl and Java support the same syntax.
For-Each Loop
foreach item in list
do stuff with item
done
Probably the most popular syntactic looping construct, and easy to see why: it’s very easy to read and understand. The for-each loop shows up in Perl, Python, Visual Basic, and a host of other languages. Because it’s usually built in to the language syntax, it can rarely be extended to non-standard container types.
Container Method Loop
list.each do |item|
do stuff with item
end
In purely object-oriented languages like Smalltalk and Ruby (shown above), looping constructs can be implemented as methods of container classes. This has the great advantages that new looping constructs can be added and standard loops can be implemented for new container types. Since the code “inside” the loop is just an anonymous function that takes a single item as its argument, it doesn’t need to know anything about the structure or type of the container.
List Comprehensions
[ item.do_stuff() for item in list ]
Although Python (syntax above) has gotten a lot of press, both good and bad, for its adoption of list comprehensions, they’ve been around a lot longer. I believe they were originally developed to describe lists in a way that looks more like mathematics. For simple patterns list comprehensions are easy to understand, but I don’t yet grok their full significance. They can be nested and combined to produce complex looping patterns that would be awkward to write with C-style iteration.
Half-Nelson Functional Loop
(map (lambda (item) do stuff with item) list)
(Update 26 July 2006: Replaced the idiotic example (map (lambda (item) (process item)) list) with the above. I’m talking about block structures in code here, using the body of the lambda like the body of a for loop in the other languages. Obviously, if your loop body was just a single function, you would just use (map #'process list). Same changes apply to the next example below.)
Functional languages, including most dialects of Lisp, usually have a map operator that takes a function and a list and applies that function successively to each element of that list. I call this the Half-Nelson Functional Loop because it’s not, to my mind, the ultimate of functional behavior. For that, we turn to…
Full-Nelson Functional Loop
((lift (lambda (item) do stuff with item)) list)
This looks pretty much like the previous example. But here, instead of map, we have lift, which takes only one argument, a function, and returns a new function that applies that function to every element of a list. That new function is then applied (here, in a Scheme-like syntax) to the list argument. I learned about lift from this blog article.
 Now, I’m not a Mac user. But a friend who is explained why she likes the Widget concept: things that are different should look different. So, I asked, does that mean that a window containing a web browser should look different from a window containing a word processor? Yes, she said.
Now, I’m not a Mac user. But a friend who is explained why she likes the Widget concept: things that are different should look different. So, I asked, does that mean that a window containing a web browser should look different from a window containing a word processor? Yes, she said.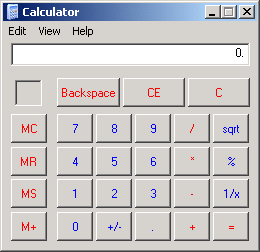 Getting back to Apple’s Widgets, they are all specialized tools. Each does a single task — calculator, address book, weather report, etc. They are not general-purpose applications, so it doesn’t make sense to put them on the same footing in the interface. For example, I almost never use the Windows Calculator because it takes too long to launch and the interface — using the default system font and colors — is hard to read. In contrast, the Dashboard calculator has a larger display and uses standard calculator symbols for multiply and divide rather than * and /. It is less consistent with the rest of the Mac GUI, but is more consistent with our notion of calculators.
Getting back to Apple’s Widgets, they are all specialized tools. Each does a single task — calculator, address book, weather report, etc. They are not general-purpose applications, so it doesn’t make sense to put them on the same footing in the interface. For example, I almost never use the Windows Calculator because it takes too long to launch and the interface — using the default system font and colors — is hard to read. In contrast, the Dashboard calculator has a larger display and uses standard calculator symbols for multiply and divide rather than * and /. It is less consistent with the rest of the Mac GUI, but is more consistent with our notion of calculators.